The term Data Lake comes across by James Dixon, the chief technology officer, which means the ad hoc nature of data. He argued that data marts have inherent data silos problems that the data lake could end while promoting data lake. Unfortunately, data lake is often deprecated as a marketing label for products that support oriented object storage, such as Hadoop.
What is a Data Lake?
A data lake represents a storage system where a considerable amount of raw data from many sources is stored in a raw, granular, or native format. Data lake stores structured, semi-structured, unstructured, or binary data for various purposes.
When held, a data lake is associated with metadata tags, which helps faster retrieval. A data lake is established within the business or organizational center or using Google and Amazon cloud services. These are generally composed of scalable and economic commodity hardware bundles or clumps. It is essential for all companies or organizations to take full advantage of their data.



A data lake example is that many companies like Amazon S3 use cloud storage or a distributed file system.
What is Cortex Data Lake?
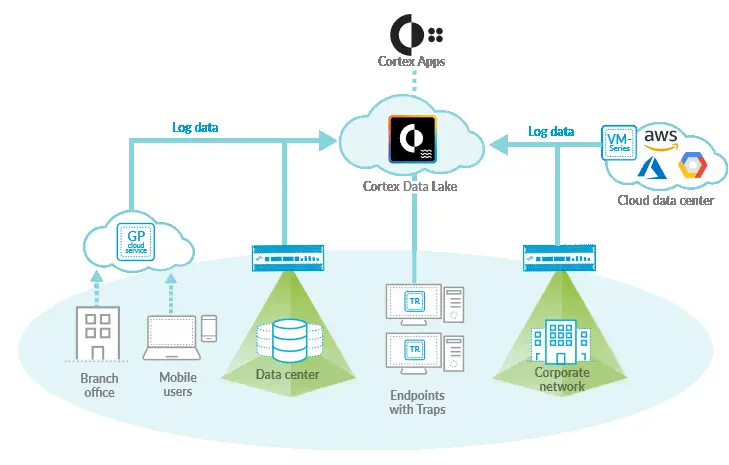
Cortex data lake represents a storage system that collects, integrates, and normalizes your enterprise’s security data. The enterprise’s goal for the cortex data lake is to identify and stop sophisticated attacks using advanced artificial intelligence (AI) and machine learning across all your enterprise’s data.
A core enterprise is a cybersecurity system. Palo Alto Networks® Cortex Data Lake “provides cloud-based, cent”realized log storage and aggregation for your on-premise, virtual (private cloud and public cloud) firewalls, for Prisma Access, and cloud-delivered services such as Cortex XDR.”
“provides cloud-based, cent”realized log storage and aggregation for your on-premise, virtual (private cloud and public cloud) firewalls, for Prisma Access, and cloud-delivered services such as Cortex XDR.”
Difference between data”warehouse and data lake
Data lakes and data warehouses are very different from their database and have various data storage strategies. The difference between them could be understood as the lake is liquid, primarily unstructured, created or fed, or dependent on other unfiltered water sources like rivers and streams. On the other hand, the warehouse is made by humans. It has shelves destined places for the things inside it, and it is restructured, while data lakes are not.
A data warehouse allows the strategic use of data. It collects data from internal and external sources and optimizes it for business purposes. The data schema is present in a data warehouse, which means a plan for data into the database upon its entry. It handles only structured data and has a preplanned schedule; in contrast, it is necessary for the data lake. It can house structured and unstructured data even if it does not have a preplanned schema for the data it houses.
Data lakes are less secure than data warehouses because data warehouses exist for a longmore extendediod, and therefore, security methods have time to mature.
Data lakes generally receive relational and nonrelational data from mobile apps and social media. Data warehouse receives online transaction processing applications to support business sales and inventory teams.
A data lake is typically used when an organization needs a data repository and can afford to apply schema on its access. In contrast, data warehouses are more useful when a massive amount of data needs to be readily available from the operational systems.
A data lake is highly agile, while data warehouses are less so.
The data lake isn’t a single or specific isn’tology. Instead, many more technologies delegate them, and some of the traders that offer these technologies are Amazon, which gives AmazonS3 limitless accessibility; Podium, which offers accessible and suite management features; Oracle, which offers Big Data Cloud; Apache offers Hadoop-the open source ecosystem which is one the most used data lake services.
Data lake advantages
It is cheap and stores raw data for low cost to implement as the technologies used to monitor the data lake are installed on low-cost hardware and are all open sources like Hadoop.

-There is no inherent data structure in the data lake, which means that any user can easily access the data lake data.
-It is flexible as it allows the data to be in its native format
-It supports the various levels of investment users as access is possible for all the users.
-The data lake is scalable as it lacks structure and is highly agile, too, allowing different types of methods to interpret data, SQL queries, etc.
Why do data lake projects fail?
Data lake projects fail because the data lake might turn into a data graveyard. Any organization that practices poor data management can lose data track in the lake no matter how much it is poured in. The other drawback is that the data lake may not provide accessibility for practical use to the organization; hence, maximizing the investment and reducing the risk of failed deployment in the data lake is essential.

Learn more about authors in Nimblefreelancer's team biography page.
- 6 Proven Ways SaaS Founders Actually Get Customers (With Real Examples) - December 17, 2025
- Facebook Ads to Get Followers! - December 27, 2024
- ClickUp vs. Slack - December 20, 2024